Microsoft揭露Whisper洩漏攻擊可識別加密流量中的AI聊天主題
Microsoft揭露一種針對遠端語言模型(Remote Language Models, RLM)新型旁路攻擊(Side-channel attack)註1的相關細節。在某些情況下,即使已強化加密保護措施,駭客也能利用這種攻擊,透過觀察網路流量來獲取模型對話主題的詳細資訊。這種人類與串流語言模型間交換的資料洩露,可能會對用戶和企業通訊的隱私構成嚴重威脅。該攻擊的代號為「Whisper Leak」(耳語洩漏)。
MicrosoftDefender安全研究團隊的安全研究人員Jonathan Bar Or和Geoff McDonald:能夠觀察加密流量的駭客(例如,網路服務供應商層的國家級駭客、本地網路上的用戶或連接到同一Wi-Fi路由器的用戶)可以利用這種網路攻擊來推斷用戶的提示是否涉及特定主題。換句話說,這種攻擊允許駭客觀察使用者與大型語言模型(Large Language Model,LLM)服務之間加密的傳輸層安全協定(Transport Layer Security, TLS)流量,提取資料封包大小和時間序列,並使用訓練好的分類器來推斷對話主題是否與敏感目標類別相符。大型語言模型 (LLM) 中的模型串流技術允許在模型產生回應的同時增量接收資料,而無需等待整個輸出計算完成。這是一種至關重要的回饋機制,因為某些回應可能需要一些時間,這取決於提示或任務的複雜性。
Microsoft展示的最新技術是,即使與人工智慧 (AI) 聊天機器人的通訊使用HTTPS加密確保了通訊內容的安全,防止被竄改。近年來,針對型語言模型的旁路攻擊層出不窮,例如,駭客可以利用型語言模型回應中加密資料封包的大小來推斷單一明文憑證(tokens)的長度,或者利用快取LLM推理結果造成的時序差異來竊取輸入(即 InputSnatch)。
Whisper Leak技術正是基於這些發現,即使在回應以憑證分組形式傳輸的情況下,串流語言模型(LLM)回應中加密資料封包大小和到達間隔時間的序列也包含足夠的資訊來對初始提示的主題進行分類。為了驗證這個假設,Microsoft表示,訓練一個二元分類器作為概念驗證,該分類器能夠使用三種不同的機器學習模型(LightGBM、Bi-LSTM和BERT)來區分特定主題提示和其他提示(即雜訊)。結果表明,來自阿里巴巴、DeepSeek、Mistral、Microsoft、OpenAI和xAI 的許多模型得分均超過98%,這意味著駭客可以透過監控與聊天機器人的隨機對話,成功標記出特定主題。相比之下,Google和Amazon的模型展現出更強的抗拒能力,這可能是因為採用憑證批次技術,但非完全免疫此類攻擊。
Microsoft表示:如果政府機構或網際網路服務供應商(Internet Service Provider, ISP)監控熱門AI聊天機器人的流量,即使所有流量都經過加密,駭客亦能成功識別出詢問特定敏感話題的用戶,無論是洗錢、政治異議還是其他受監控的主題。(如圖1所示)
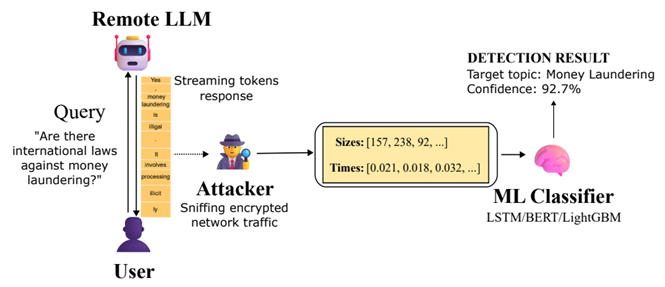
圖1:Whisper Leak攻擊鏈
研究人員發現,隨著駭客收集的訓練樣本越來越多,Whisper Leak 的有效性也會隨之提高,使其成為實際存在的威脅。OpenAI、Mistral、Microsoft和xAI均已部署緩解措施來應對此類安全風險。補充報告:結合更複雜的攻擊模型以及多輪對話(或同一用戶的多條對話)中更豐富的模式,這意味更具耐心和資源的網路駭客可能獲得成果更高成功率。OpenAI、Microsoft和Mistral設計的一項有效應對措施是在每個回應中添加「長度可變的隨機文字序列」,從而掩蓋每個標記的長度,使旁路攻擊失效。Microsoft並建議,在使用公共Wi-Fi等不可信網路時,如果用戶擔心與AI聊天機器人互動時的隱私問題,應避免討論高度敏感的話題;使用VPN來增加一層保護;使用非串流LLM 模型;以及切換到已實施緩解措施的供應商。
此揭露源自於一項針對八款開源LLM最新評估。這八款LLM 分別來自阿里巴巴 (Qwen3-32B)、DeepSeek (v3.1)、Google (Gemma 3-1B-IT)、Meta (Llama 3.3-70B-Instruct)、Microsoft (Phi-4)、Mistral (Large-2,又名Large-Inc-2047) (NVV-T3),又名 Large-10-2047 4.5-Air)。評估發現,這些LLM極易受到對抗性操縱,尤其是在多回合攻擊方面。(如圖2所示)
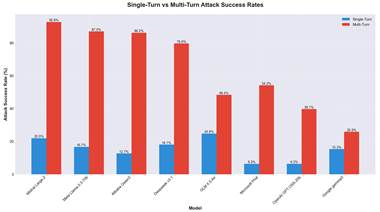
圖2:對八款開源LLM最新評估
CISCO人工智慧防禦部門的研究人員Amy Chang、Nicholas Conley、Harish Santhanalakshmi Ganesan和Adam Swanda指出:這些結果凸顯當前開放式權重模型在長時間交互過程中維持安全防護方面的系統性缺陷。評估認為對齊策略和實驗室優先級對模型的韌性有顯著影響:以能力為導向的模型,例如Llama 3.3和Qwen 3,反映出更高的多輪攻擊敏感性,而以安全為導向的設計,例如Google Gemma 3,則表現出更均衡的性能。發現表明,採用開源模型的組織在缺乏額外安全防護措施的情況下可能會面臨營運風險。自OpenAI ChatGPT於2022年11月公開發布以來,越來越多的研究揭示LLM 和AI聊天機器人的根本性安全漏洞。因此,開發者在將此類功能整合到工作流程中時,必須實施充分的安全控制措施,對開源模型進行微調以增強其抵禦越獄和其他攻擊的能力,定期進行AI紅隊演練,並實施與既定用例相符的嚴格系統提示。
註1: 旁道攻擊(Side-channel attack):是在密碼學中,又稱側信道攻擊、邊信道攻擊一種攻擊方式,它基於從密碼系統的物理實現中獲取的資訊而非暴力破解法或是演算法中的理論性弱點(較之密碼分析)。例如:時間資訊、功率消耗、電磁洩露或甚是聲音可以提供額外的資訊來源,這可被利用於對系統的進一步破解。某些側信道攻擊還要求駭客有關於密碼系統內部操作的技術性資訊,不過,其他諸如差分電力分析的方法在黑盒攻擊中效果明顯。
本文參考自:https://thehackernews.com/2025/11/microsoft-uncovers-whisper-leak-attack.html